Effectivate C++
习惯C++
01
视C++为一个语言联邦
次语言:
- C语言:以C语言为基础。
- Object-Oriented C++:面向对象程序设计
- Template C++:泛型编程
- STL:程序库
02
尽量以const, enum, inline替代 #define
1 |
|
- 对于单纯常量,最好以const对象或enums替换#defines
- 对于形似函数的宏(macros),最好改用inline函数替换#defines
03
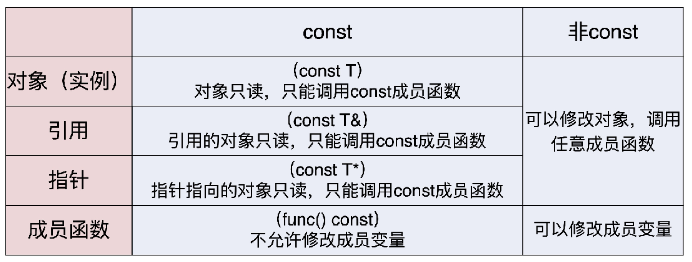
尽可能使用const
04
确定对象在被使用前已先被初始化
C++资源管理
堆(heap)
在内存管理的语境下,堆——动态分配内存的区域,有别于数据结构的堆
此内存被分配后需要手动释放,否则造成内存泄漏。
自由存储区——free store
- 特指用new和delete来分配和释放内存区域
- new和delete的底层通常使用malloc和free实现
malloc和free的操作区域是heap
栈(stack)
在内存管理的语境下,栈——函数调用过程中产生的本地变量和调用数据的区域,和数据结构的栈高度类似,满足FIFO。
RALL
Resource Acquisition Is Initialization——C++是主流编程语言中唯一依赖RALL做资源管理,依托栈和析构函数
在包括 x86 在内的大部分计算机体系架构中,栈的增长方向是低地址,因而上方意味着低地址。
重新认识C++
程序的生命周期
编码(Coding)→预处理(Pre-processing)→编译(Compiling)→运行(Running)
编码
最基本的要求是遵循语言规范和设计文档,再者还有代码规范、注释规范、设计模式、编程惯用法等
代码风格
- 空格和空行
- 留白的艺术——像‘写诗’一样去写代码
- 起个好名字
- 变量、函数名和名字空间用 snake_case,全局变量加“g_”前缀;
- 自定义类名用 CamelCase,成员函数用 snake_case,成员变量加“m_”前缀;
- 宏和常量应当全大写,单词之间用下划线连接;
- 尽量不要用下划线作为变量的前缀或者后缀(比如 _local、name_),很难识别;
- 注释
预处理
C/C++程序独有。预处理器(Pro-processer)起作用。“预处理”的目的是文字替换,即各种预处理指令,比如 #include、#define、#if 等,实现“预处理编程”。
预处理阶段编程的操作目标是“源码”,用各种指令控制预处理器,把源码
改造成另一种形式,就像是捏橡皮泥一样。
- 预处理指令都以符号“#”开头
- 单独的一个“#”也是一个预处理指令,叫“空指令”
- “#include”,它的作用是“包含文件”,可以包含任意的文件
- 使用“#if 1”“#if 0”来显式启用或者禁用大段代码,比“/* …*/”的注释方式安全
编译
编译和链接。经过编译器和链接器的“锤炼”,生成可在计算机上运行的二进制机器码。编译的过程中,编译器还会根据 C++ 语言规则检查程序的语法、语义是否正确,发现错误就会产生“编译失败”。这是最基本的 C++“静态检查”。
属性
C++11,标准委员会认识到了“编译指令”的好处,把“民间”用法升级为“官方版本”,起名叫“属性”。可以理解为给变量、函数、类等“贴”上一个编译阶段的“标签”,方便编译器识别处理。
“属性”没有新增关键字,而是用两对方括号形式“[[…]]”,方括号的中间就是属性标签。
1 | [[noreturn]] // 属性标签 |
C11 里只定义了两个属性:“noreturn”和“carries_dependency”,它们
基本上没什么大用处。C14 增加了一个比较实用的属性“deprecated”,用来标记不推
荐使用的变量、函数或者类,也就是被“废弃”。
比如,原来写了一个函数 old_func(),后来觉得不够好,就另外重写了一个完全不同的新函数。但是,那个老函数已经发布出去被不少人用了,立即删除不太可能,该怎么办呢?
这个时候,可以让“属性”发挥威力了。你可以给函数加上一个“deprecated”的编译期标签,再加上一些说明文字:
1 | [[deprecated("deadline:2020-12-31")]] |
于是,任何用到这个函数的程序都会在编译时看到这个标签,报出一条警告:
1 | warning: ‘int old_func()’ is deprecated: deadline:2020-12-31 [-Wdeprecated-decl |
程序能够正常编译,但这种强制的警告形式会“提醒”用户旧接口已经被废弃了,应该尽快迁移到新接口。这种形式比毫无约束力的文档或者注释要好得多。
静态断言(static_assert)
static_assert 运行在编译阶段,只能看到编译时的常数和类型,看不到运行时的变量、指针、内存数据等,是“静态”的。
编程范式
编程范式(Paradigm)。“编程范式”是一种“方法论”,就是指导你编写代码的一些思路、规则、习惯、定式和常用语。
运行
CPU 利用率通常是评价程序运行的好坏最直观、最容易获取的指标,优化它是提升系统性能最快速的手段。
系统级工具
四个“高性价比”的工具:top、pstack、strace 和 perf。它们用起来很简单,而且实用性很强,可以观测到程序的很多外部参数和内部函数调用,由内而外、由表及里地分析程序性能。
某个进程 CPU 使用率太高,怀疑有问题,那我就要深入进程内部,看看到底是哪些操作消耗了 CPU。这时,我们可以选用两个工具:pstack 和 strace。
pstack 可以打印出进程的调用栈信息,有点像是给正在运行的进程拍了个快照,你能看到某个时刻的进程里调用的函数和关系,对进程的运行有个初步的印象。
pstack 显示的只是进程的一个“静态截面”,信息量还是有点少,而 strace 可以显示出进程的正在运行的系统调用,实时查看进程与系统内核交换了哪些信息。
perf 可以说是 pstack 和 strace 的“高级版”,它按照固定的频率去“采样”,相当于连续执行多次的 pstack,然后再统计函数的调用次数,算出百分比。只要采样的频率足够大,把这些“瞬时截面”组合在一起,就可以得到进程运行时的可信数据,比较全面地描述出 CPU 使用情况。
常用的 perf 命令是“perf top -K -p xxx”,按 CPU 使用率排序,只看用户空间的调用。
源码级工具
推荐一个专业的源码级性能分析工具:Google Performance Tools,简称为 gperftools。它是一个 C++ 工具集,包含了几个专门的性能分析工具(还有一个高效的内存分配器 tcmalloc),分析效果直观、友好、易理解,被广泛地应用于很多系统,经过了充分的实际验证。
编译运行后会得到一个“case1.perf”的文件,里面就是 gperftools 的分析数据,但它是
二进制的,不能直接查看,如果想要获得可读的信息,需要另外一个工具脚本 pprof。但是,pprof 脚本并不含在 apt-get 的安装包里,所以,你还要从GitHub上下载源码,然后用“–text”选项,就可以输出文本形式的分析报告。pprof 也能输出图形化的分析报告,支持有向图和火焰图,需要你提前安装 Graphviz和 FlameGraph。
怎样写出“好”的类
设计思想
抽象(Abstraction)和封装(Encapsulation)
实现原则
- 在设计类的时候尽量少用继承和虚函数。
- 使用特殊标识符“final”可以禁止类被继承,简化类的层次关系。
编码准则
在必须使用继承的场合,建议你只使用 public 继承,避免使用 virtual、protected
常用技巧
- “委托构造”(delegating constructor)
1 | class DemoDelegating final |
- “成员变量初始化”(In-class member initializer)
1 | class DemoInit final |
- “类型别名”(Type Alias)
1 | using uint_t = unsigned int; // using别名 |
语言特性
自动类型推导
关键字 auto
- auto 总是推导出“值类型”,绝不会是“引用”;
- auto 可以附加上 const、volatile、*、& 这样的类型修饰符,得到新的类型。
1 | auto x = 0L; // 自动推导为long |
C++ 的“自动类型推导”还有另外一个关键字:decltype
1 | int x = 0; // 整型变量 |
decltype 不仅能够推导出值类型,还能够推导出引用类型,也就是表达式的“原始类
型”。
C++14 增加了一个“decltype(auto)”的形式,既可以精确推导类型,又能像
auto 一样方便使用。
1 | int x = 0; // 整型变量 |
auto 还有一个“最佳实践”,就是“range-based for”,不需要关心容器元素类型、迭
代器返回值和首末位置,就能非常轻松地完成遍历操作。不过,为了保证效率,最好使
用“const auto&”或者“auto&”。
1 | vector<int> v = {2,3,5,7,11}; // vector顺序容器 |
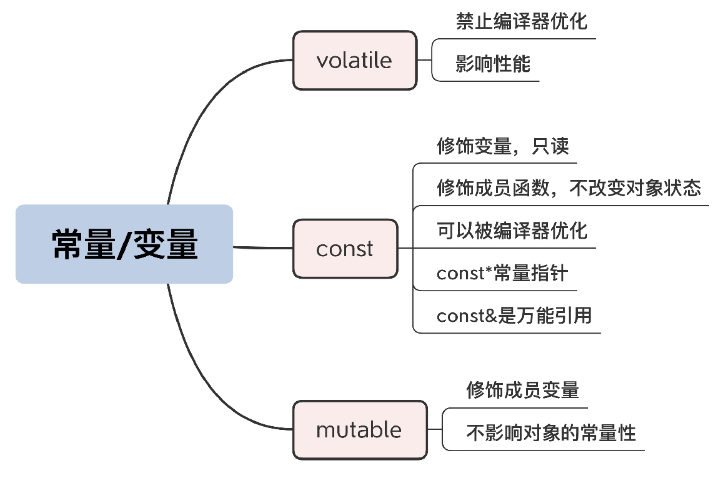
常量/变量
const/volatile/mutable
- const
1 | // 需要加上volatile修饰,运行时才能看到效果 |
我从来不用“* const”的形式,也建议你最好不要用,而且这种形式在实际开发时也确实没有多大作用(除非你想“炫技”)。
- mutable
用来修饰成员变量,允许 const 成员函数修改,mutable 变量的变化不影响对象的常量性,但要小心不要误用损坏对象。你今后再写类的时候,就要认真想一想,哪些操作改变了内部状态,哪些操作没改变内部状态,对于只读的函数,就要加上 const 修饰。写错了也不用怕,编译器会帮你检查出来。
- volatile
它表示变量可能会被“不被察觉”地修改,禁止编译器优化,影响性能,应当少用。
尽可能多用 const,让代码更安全
智能指针
常用的有两种智能指针,分别是 unique_ptr 和 shared_ptr
- unique_ptr
unique_ptr 是最简单、最容易使用的一个智能指针,在声明的时候必须用模板参数指定类型:
1 | unique_ptr<int> ptr1(new int(10)); // int智能指针 |
unique_ptr 虽然名字叫指针,用起来也很像,但它实际上并不是指针,而是一个对象。所以,不要企图对它调用 delete,它会自动管理初始化时的指针,在离开作用域时析构释放内存。
它也没有定义加减运算,不能随意移动指针地址,完全避免了指针越界等危险。
未初始化的 unique_ptr 表示空指针,这样就相当于直接操作了空指针,运行时就会产生致命的错误。
为了避免这种低级错误,可以调用工厂函数 make_unique(),强制创建智能指针的时候必须初始化。同时还可以利用自动类型推导 auto,少写一些代码:
1 | auto ptr3 = make_unique<int>(42); // 工厂函数创建智能指针 |
尽量不要对 unique_ptr 执行赋值操作
- shared_ptr
1 | shared_ptr<int> ptr1(new int(10)); // int智能指针 |
它的所有权是可以被安全共享的,也就是说支持拷贝赋值。
Exception
- 异常的处理流程是完全独立的,throw 抛出异常后就可以不用管了,错误处理代码都集中在专门的 catch 块里。这样就彻底分离了业务逻辑与错误逻辑,看起来更清楚。
- 异常是绝对不能被忽略的,必须被处理。如果你有意或者无意不写 catch 捕获异常,那么它会一直向上传播出去,直至找到一个能够处理的 catch 块。如果实在没有,那就会导致程序立即停止运行,明白地提示你发生了错误,而不会“坚持带病工作”。
- 异常可以用在错误码无法使用的场合,这也算是 C++ 的“私人原因”。因为它比 C 语言多了构造 / 析构函数、操作符重载等新特性,有的函数根本就没有返回值,或者返回值无法表示错误,而全局的 errno 实在是“太不优雅”了,与 C++ 的理念不符,所以也必须使用异常来报告错误。
函数式编程 lambda
1 | auto func = [](int x) // 定义一个lambda表达式 |
lambda 表达式除了可以像普通函数那样被调用,还有一个普通函数所不具备的特殊本领,就是可以“捕获”外部变量,在内部的代码里直接操作。
1 | int n = 10; // 一个外部变量 |
C++ 没有为 lambda 表达式引入新的关键字,并没有“lambda”这样的词汇,而是用了一个特殊的形式“[]”,术语叫“lambda 引出符”(lambda introducer)。在 lambda 引出符后面,就可以像普通函数那样,用圆括号声明入口参数,用花括号定义函数体。
标准库
字符串
-
字面量后缀
1
2using namespace std::literals::string_literals; //必须打开名字空间
auto str = "std string"s; // 后缀s,表示是标准字符串,直接类型推导 -
原始字符串
1
auto str = R"(nier:automata)"; // 原始字符串:nier:automata
-
字符串转换函数
1
2
3assert(stoi("42") == 42); // 字符串转整数
assert(stol("253") == 253L); // 字符串转长整数
assert(stod("2.0") == 2.0); // 字符串转浮点数 -
字符串视图类
正则表达式
C++ 正则表达式主要有两个类。
- regex:表示一个正则表达式,是 basic_regex 的特化形式;
- smatch:表示正则表达式的匹配结果,是 match_results 的特化形式。
C++ 正则匹配有三个算法,注意它们都是“只读”的,不会变动原字符串。
- regex_match():完全匹配一个字符串;
- regex_search():在字符串里查找一个正则匹配;
- regex_replace():正则查找再做替换。
容器
容器,就是能够“容纳”“存放”元素的一些数据结构。
容器里存储的是元素的拷贝、副本,而不是引用。
- 顺序容器
- 即数据结构里的线性表,一共有 5 种:array、vector、deque、list、forward_list
- 连续存储的数组:array、vector 和 deque。
- array 和 vector 直接对应 C 的内置数组,内存布局与 C 完全兼容,所以是开销最低、速度最快的容器。区别在于,array 是静态数组,而 vector 是动态数组。
- deque 也是动态数组,它可以在两端高效地插入删除元素,这也是它的名字double-end queue 的来历,而 vector 则只能用 push_back 在末端追加元素。
- 指针结构的链表:list 和 forward_list
- list 是双向链表,而 forward_list是单向链表。
- 有序容器
- C++ 的有序容器使用的是树结构,通常是红黑树——有着最好查找性能的二叉树。
- 标准库里一共有四种有序容器:set/multiset 和 map/multimap。set 是集合,map 是关联数组(在其他语言里也叫“字典”)。
- 有 multi 前缀的容器表示可以容纳重复的 key,内部结构与无前缀的相同,所以也可以认为只有两种有序容器。
- 集合关系就用 set,关联数组就用 map。
- 无序容器
- unordered_set/unordered_multiset、unordered_map/unordered_multimap。
- 内部数据结构不是红黑树,而是散列表(也叫哈希表,hash table)
- 如果只想要单纯的集合、字典,没有排序需求,就应该用无序容器,没有比较排序的成本,它的速度就会非常快。
算法
迭代器
1 | array<int, 5> arr = {0,1,2,3,4}; // array静态数组容器 |
for_each()
1 | vector<int> v = {3,5,1,7,10}; // vector容器 |
排序
- 常见问题对应的算法:
- 要求排序后仍然保持元素的相对顺序,应该用 stable_sort,它是稳定的;
- 选出前几名(TopN),应该用 partial_sort;
- 选出前几名,但不要求再排出名次(BestN),应该用 nth_element;
- 中位数(Median)、百分位数(Percentile),还是用 nth_element;
- 按照某种规则把元素划分成两组,用 partition;
- 第一名和最后一名,用 minmax_element。

查找
并发
“读而不写”就不会有数据竞争。
- 多线程是并发最常用的实现方式,好处是任务并行、避免阻塞,坏处是开发难度高,有数据竞争、死锁等很多“坑”;
- call_once() 实现了仅调用一次的功能,避免多线程初始化时的冲突;
- thread_local 实现了线程局部存储,让每个线程都独立访问数据,互不干扰;
- atomic 实现了原子化变量,可以用作线程安全的计数器,也可以实现无锁数据结构;
- async() 启动一个异步任务,相当于开了一个线程,但内部通常会有优化,比直接使用线程更好。
技能进阶
序列化/反序列化
JSON
JSON 是一种轻量级的数据交换格式,采用纯文本表示,所以是“human readable”,阅
读和修改都很方便。
JSON for Modern C++ 可能不是最小最快的 JSON 解析工具,但功能足够完善,而且使
用方便,仅需要包含一个头文件“json.hpp”,没有外部依赖,也不需要额外的安装、编
译、链接工作,适合快速上手开发。
1 | git clone git@github.com:nlohmann/json.git |
MessagePack
它也是一种轻量级的数据交换格式,与 JSON 的不同之处在于它不是纯文本,而是二进制。由于二进制这个特点,MessagePack 也得到了广泛的应用,著名的有 Redis、Pinterest。
1 | git clone git@github.com:msgpack/msgpack-c.git |
ProtoBuffer
通常简称为 PB,由 Google 出品。PB 也是一种二进制的数据格式,但毕竟是工业级产品,所以没有 JSON 和 MessagePack那么“轻”,相关的东西比较多,要安装一个预处理器和开发库,编译时还要链接动态库(-lprotobuf):
1 | apt-get install protobuf-compiler |
PB 的另一个特点是数据有“模式”(schema),必须要先写一个 IDL(Interface Description Language)文件,定义好数据结构,只有预先定义了的数据结构,才能被序列化和反序列化。
网络通信
libcurl:高可移植、功能丰富的通信库
cpr:更现代、更易用的通信库
cpr 是对 libcurl 的一个 C11 封装,使用了很多现代 C 的高级特性,对外的接口模仿了 Python 的 requests 库,非常简单易用。
1 | git clone git@github.com:whoshuu/cpr.git |
ZMQ:高效、快速、多功能的通信库
作为消息队列,ZMQ 的另一大特点是零配置零维护零成本,不需要搭建额外的代理服务器,只要安装了开发库就能够直接使用,相当于把消息队列功能直接嵌入到你的应用程序里:
1 | apt-get install libzmq3-dev |
ZMQ 是一个高级的网络通信库,支持多种通信模式,可以把消息队列功能直接嵌入应用程序,搭建出高效、灵活、免管理的分布式系统。
脚本语言
Python
pybind11 完全基于现代 C++ 开发(C11 以上),所以没有兼容旧系统的负担。它使用了大量的现代 C 特性,不仅代码干净整齐,运行效率也更高。
pybind11 支持 Python2.7、Python3 和 PyPy,这里我用的是 Python3:
1 | apt-get install python3-dev |
Lua
第二个脚本语言是小巧高效的 Lua,号称是“最快的脚本语言”。
1 | git clone git@github.com:openresty/luajit2.git |
总结
设计模式
常用有 5 个原则,也就是常说的“SOLID”。
- SRP,单一职责(Single ResponsibilityPrinciple);
- OCP,开闭(Open Closed Principle);
- LSP,里氏替换(Liskov Substitution Principle);
- ISP,接口隔离(Interface-Segregation Principle);
- DIP,依赖反转,有的时候也叫依赖倒置(Dependency Inversion Principle)。