include <iostream> usingnamespace std; template<typename T> //整数或浮点数皆可使用,若要使用类(class)或结构体(struct)时必须重载大于(>)运算符 voidbubble_sort(T arr[], int len){ int i, j; for (i = 0; i < len - 1; i++) for (j = 0; j < len - 1 - i; j++) if (arr[j] > arr[j + 1]) swap(arr[j], arr[j + 1]); } intmain(){ int arr[] = { 61, 17, 29, 22, 34, 60, 72, 21, 50, 1, 62 }; int len = (int) sizeof(arr) / sizeof(*arr); bubble_sort(arr, len); for (int i = 0; i < len; i++) cout << arr[i] << ' '; cout << endl; float arrf[] = { 17.5, 19.1, 0.6, 1.9, 10.5, 12.4, 3.8, 19.7, 1.5, 25.4, 28.6, 4.4, 23.8, 5.4 }; len = (float) sizeof(arrf) / sizeof(*arrf); bubble_sort(arrf, len); for (int i = 0; i < len; i++) cout << arrf[i] << ' '<<endl; return0; }
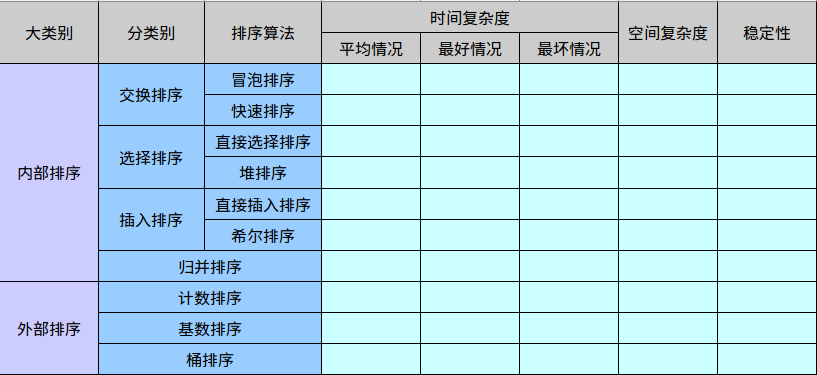
Selection sort
Selection sort is a simple and intuitive sorting algorithm that is O(n²) time complex no matter what data goes in. So when using it, the smaller the data size, the better. The only advantage is that it doesn’t take up extra memory space.
算法步骤
First, find the smallest (large) element in the unsorted sequence and store it at the beginning of the sorted sequence.
Then find the smallest (large) element from the remaining unsorted elements and put it at the end of the sorted sequence.
Repeat the second step until all elements are sorted.
1 2 3 4 5 6 7 8 9 10
template<typename T> voidselection_sort(vector<T>& arr){ for (int i = 0; i < arr.size() - 1; i++) { int min = i; for (int j = i + 1; j < arr.size(); j++) if (arr[j] < arr[min]) min = j; swap(arr[i], arr[min]); } }
Insertion sort
The code implementation of insertion sort is not as simple and brutal as bubble sort and selection sort, but its principle should be the easiest to understand, because anyone who has played poker should be able to understand it in seconds. Insertion sort is one of the simplest and most intuitive sorting algorithms. It works by constructing an ordered sequence, and for unsorted data, scanning backward and forward in the sorted sequence to find the appropriate position and insert it.
Insertion sort, like bubble sort, also has an optimization algorithm called split-half insertion.
1 2 3 4 5 6 7 8 9 10 11
voidinsertion_sort(int arr[],int len){ for(int i=1;i<len;i++){ int key=arr[i]; int j=i-1; while((j>=0) && (key<arr[j])){ arr[j+1]=arr[j]; j--; } arr[j+1]=key; } }
Shell sort
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
template<typename T> voidshell_sort(T array[], int length){ int h = 1; while (h < length / 3) { h = 3 * h + 1; } while (h >= 1) { for (int i = h; i < length; i++) { for (int j = i; j >= h && array[j] < array[j - h]; j -= h) { swap(array[j], array[j - h]); } } h = h / 3; } }
template <typename T> voidquick_sort_recursive(T arr[], int start, int end){ if (start >= end) return; T mid = arr[end]; int left = start, right = end - 1; while (left < right) { //在整个范围内搜寻比枢纽元值小或大的元素,然后将左侧元素与右侧元素交换 while (arr[left] < mid && left < right) //试图在左侧找到一个比枢纽元更大的元素 left++; while (arr[right] >= mid && left < right) //试图在右侧找到一个比枢纽元更小的元素 right--; std::swap(arr[left], arr[right]); //交换元素 } if (arr[left] >= arr[end]) std::swap(arr[left], arr[end]); else left++; quick_sort_recursive(arr, start, left - 1); quick_sort_recursive(arr, left + 1, end); } template <typename T> voidquick_sort(T arr[], int len){ quick_sort_recursive(arr, 0, len - 1); }
Time complexity
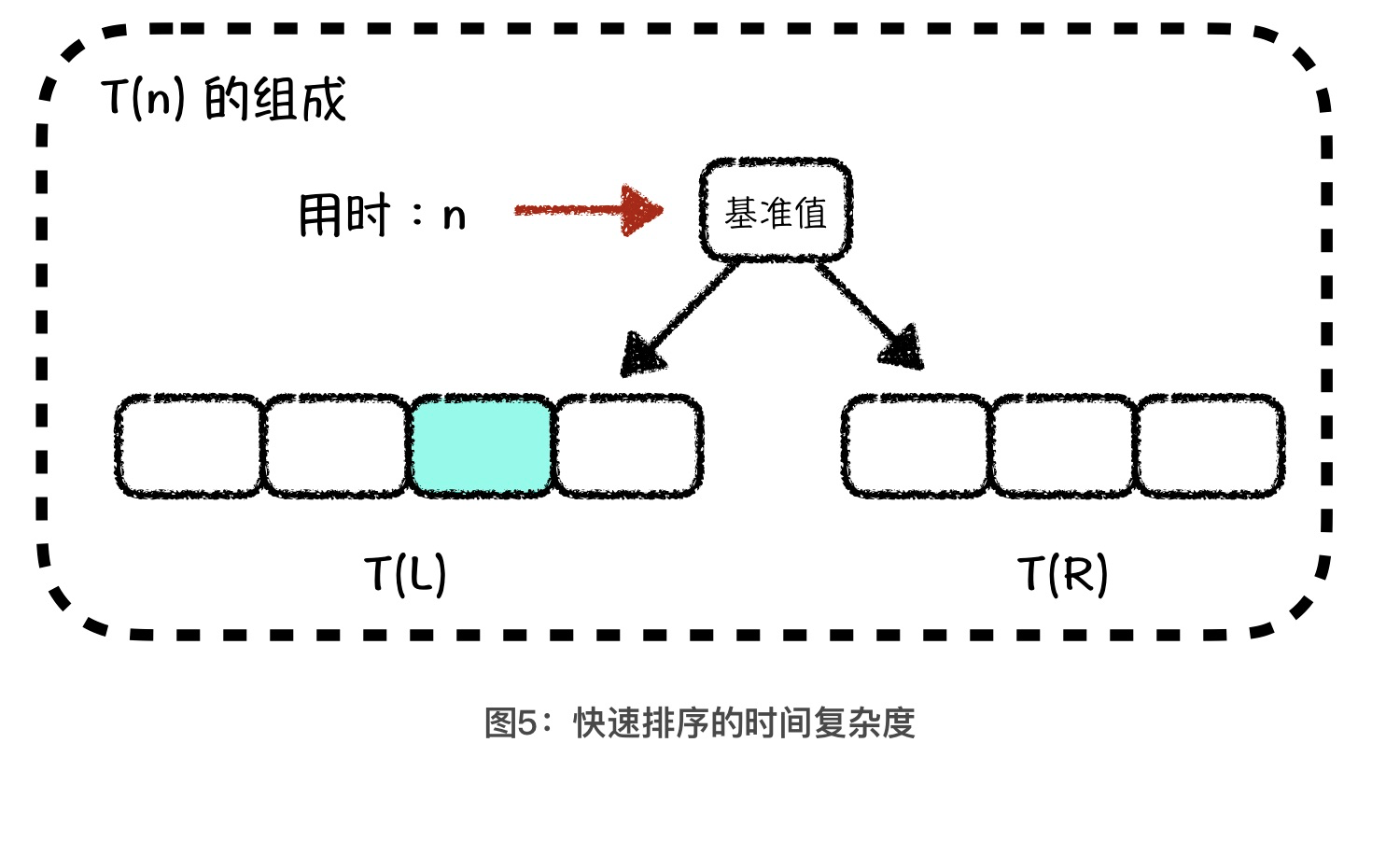
During the partition process, both the head and tail pointers are scanned cyclically to the last position where the base value was placed. Thus, the head and tail pointer scans together are equivalent to scanning the entire region of the array to be sorted. Therefore, we can conclude that the time complexity of a single partition operation is O(n). The formula for the overall time complexity: T(n) = n + T(L) + T®.
Time complexity:O(nlog2n)
Optimization
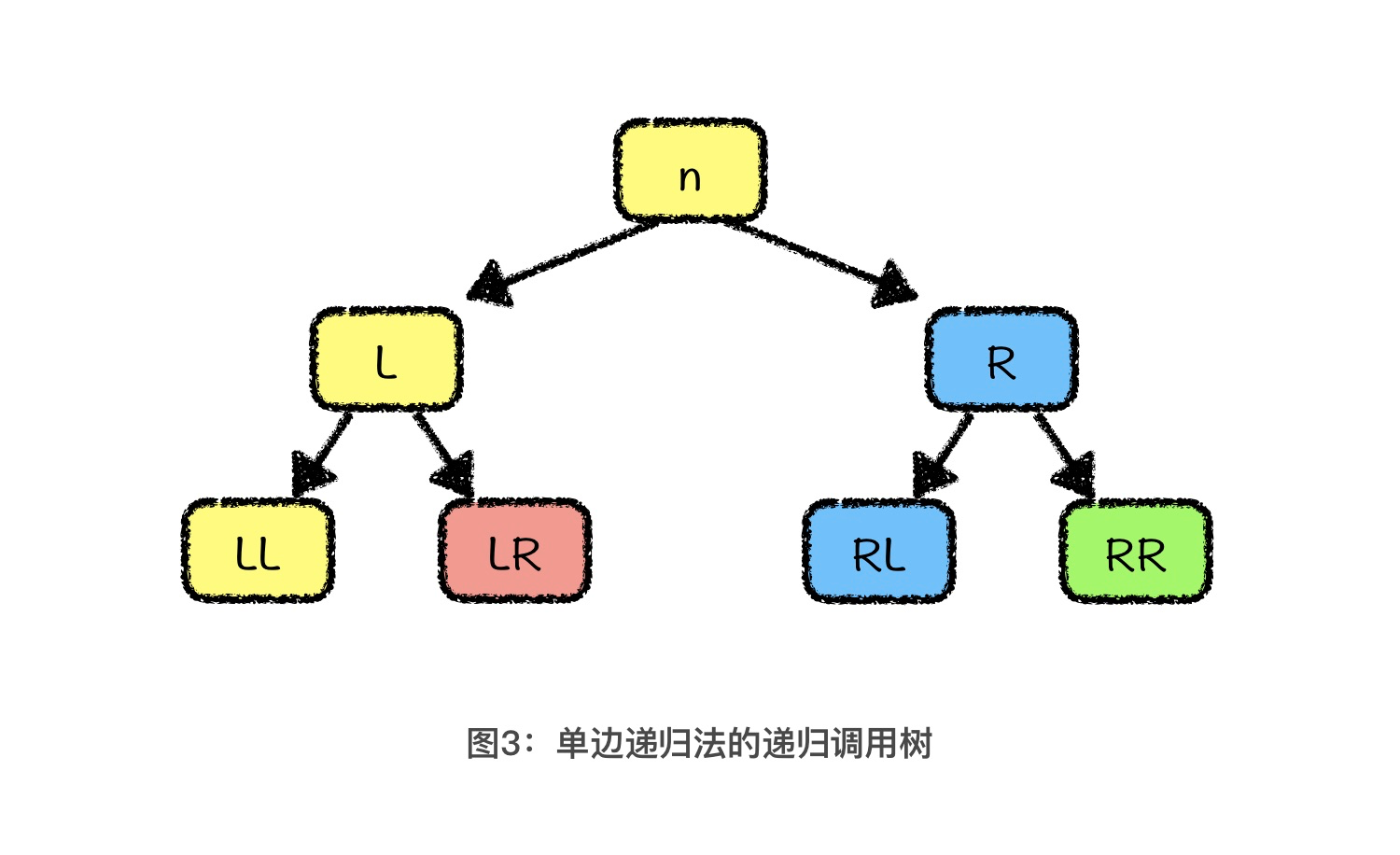
One-sided recursive optimization
Mode:when this layer has finished the partition operation, let this layer continue to complete the partition operation to the left of the base value, while the sorting work to the right of the base value is left to the next layer of recursive functions to handle.
function is called 4 times.
Without the method, the actual number is 7.
1 2 3 4 5 6 7 8 9 10 11 12
voidquick_sort(int *arr, int l, int r) { while (l < r) { // 进行一轮 partition 操作 // 获得基准值的位置 int ind = partition(arr, l, r); // 右侧正常调用递归函数 quick_sort(arr, ind + 1, r); // 用本层处理左侧的排序 r = ind - 1; } return ; }
Optimization of benchmark value selection
three-point middle method is to take the three values of the head, tail and middle elements of the sorting interval in each round, and then use the middle value after they are sorted as the base value for the current round.For example, suppose the three values of this round are 2, 9 and 7, and the middle value is 7, so the base value of this round is 7.
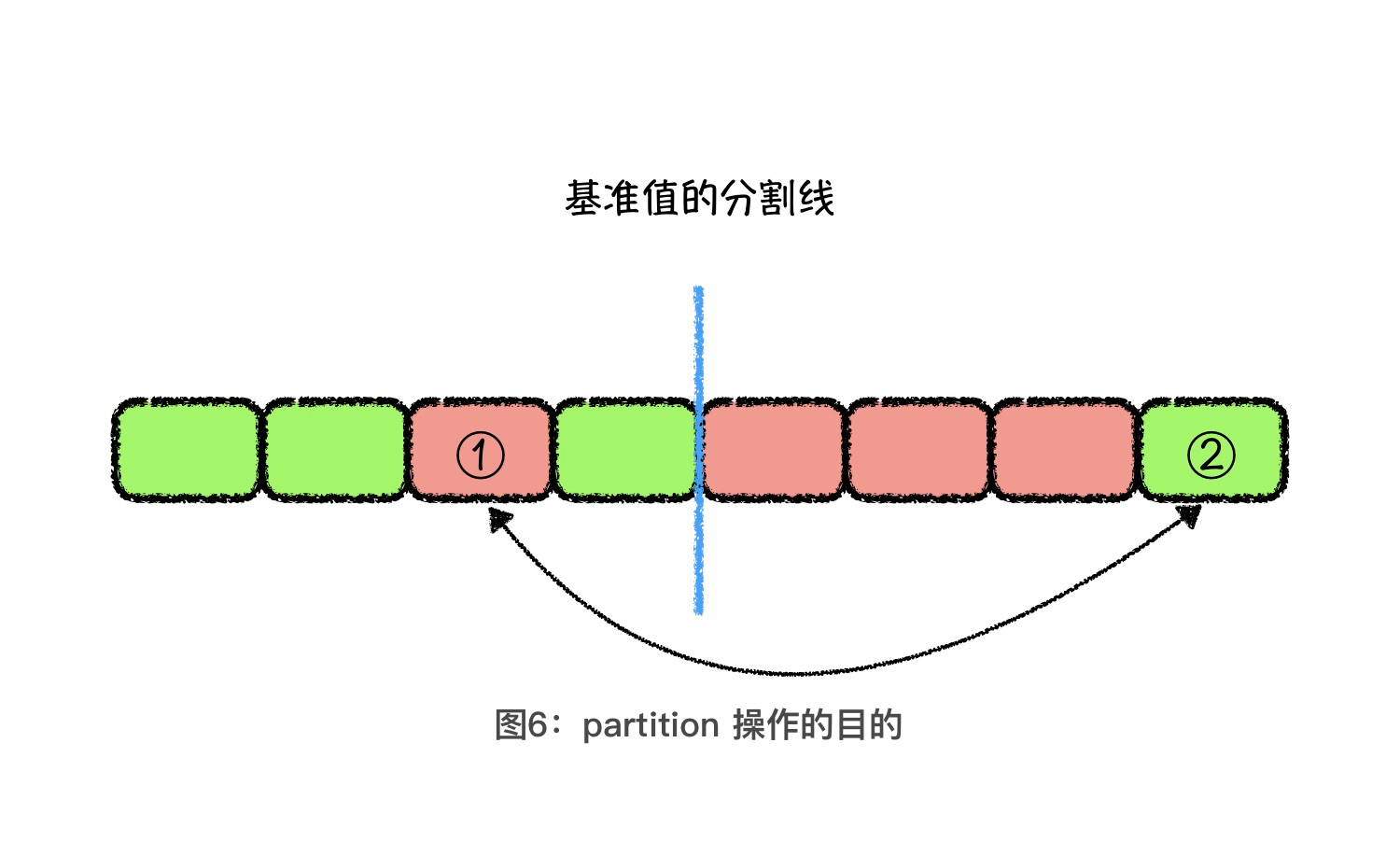
Partition Operation Optimization
Let the head pointer look backward for red elements and the tail pointer look forward for green elements, then swap the elements pointed by the head and tail pointers and repeat the process until the head and tail pointers are interleaved and stop.